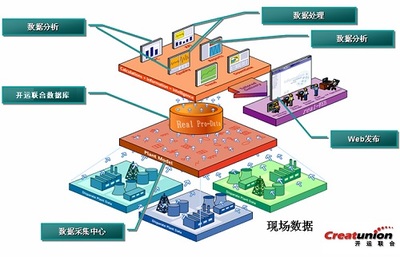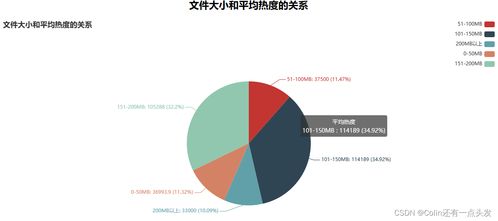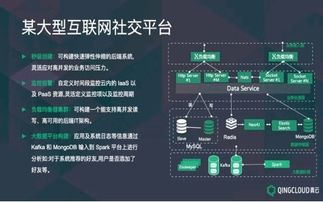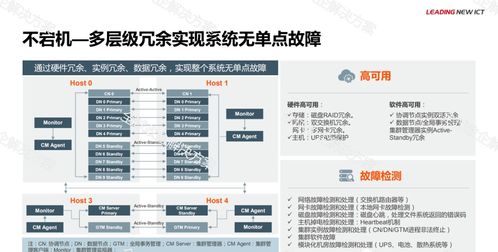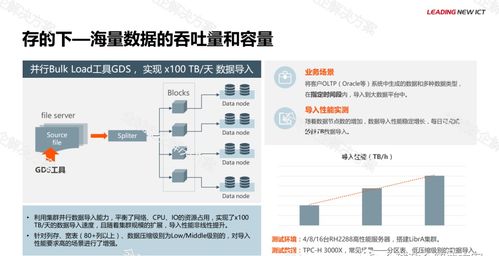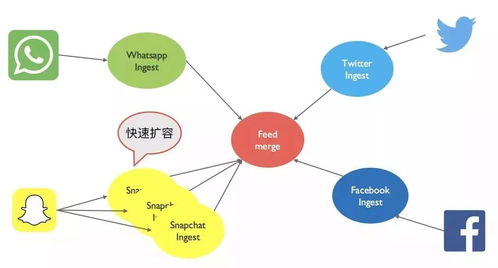
在当今的软件开发中,微服务架构因其高可扩展性、灵活性和独立性而备受青睐。在微服务架构下,数据设计和数据处理服务面临着独特的挑战和机遇。本文旨在快速帮助读者理解微服务架构下的数据设计原则和数据处理服务的实现。
微服务架构的数据设计核心原则
微服务架构强调服务的松耦合和独立部署,因此数据设计必须遵循以下关键原则:
- 数据自治:每个微服务应拥有自己的数据库或数据存储,避免直接共享数据库。这确保了服务的独立性,减少了服务间的依赖,从而提高了系统的可维护性和可扩展性。例如,订单服务可以拥有独立的订单数据库,而用户服务则管理用户数据。
- 领域驱动设计(DDD):通过将系统划分为有界的上下文,每个微服务负责特定的业务领域。数据模型应围绕这些领域设计,确保数据的一致性和完整性。这有助于避免数据冗余和冲突,例如在电商系统中,商品服务和库存服务可以各自维护相关数据。
- 事件驱动架构:为了在服务间同步数据,可以采用事件驱动的方式。当一个服务的数据发生变化时,它发布一个事件,其他服务订阅并更新自己的数据。这减少了直接调用,提高了系统的响应性和可靠性。例如,当用户注册时,用户服务发布“用户创建”事件,通知其他服务如通知服务或推荐服务。
- 数据一致性考虑:在分布式环境中,强一致性可能难以实现,因此常采用最终一致性。通过使用 saga 模式或两阶段提交等机制,处理跨服务的事务,确保数据在长时间内达到一致状态。
数据处理服务的实现关键点
数据处理服务在微服务架构中负责数据的采集、转换、存储和分析。以下是设计和实现这些服务的要点:
- 服务拆分与职责分离:将数据处理功能拆分为独立的微服务,如数据摄取服务、数据清洗服务和数据分析服务。每个服务专注于单一职责,便于开发、测试和部署。例如,一个实时数据处理服务可以独立于批处理服务运行。
- 使用消息队列和流处理:为了处理高并发和数据流,集成消息中间件(如 Kafka 或 RabbitMQ)和流处理框架(如 Apache Flink 或 Spark Streaming)。这支持实时数据处理,例如,在日志分析或用户行为跟踪中,数据可以实时流入处理管道。
- 数据存储策略:根据数据需求选择合适的存储方案,如关系型数据库(MySQL)用于事务性数据,NoSQL(MongoDB)用于灵活模式,或数据湖用于大数据分析。确保数据服务能够高效读写,并支持水平扩展。
- 监控与容错:实施全面的监控和日志机制,使用工具如 Prometheus 和 ELK 栈跟踪数据流和服务健康状态。设计容错机制,如重试、断路器和数据备份,以防止数据丢失和服务中断。
- 安全与合规:在数据处理中,确保数据加密、访问控制和合规性(如 GDPR)。通过 API 网关和身份验证服务保护数据接口,防止未授权访问。
总结
微服务架构下的数据设计和数据处理服务需要平衡独立性、一致性和性能。通过遵循数据自治、事件驱动和领域驱动原则,并结合现代工具实现数据处理服务,可以构建出高效、可扩展的系统。实践时,建议从简单场景开始,逐步迭代,以应对复杂的业务需求。记住,关键在于持续学习和适应变化的技术环境。