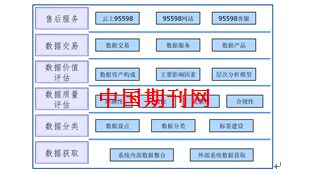
随着企业数字化转型的深入,数据量呈爆炸式增长,数据库的运维与管理日益复杂。传统依赖人工的数据库管理(DBA)模式在效率、成本与风险控制上遭遇瓶颈。腾讯云数据库自治服务(TencentDB Autonomous Service)应运而生,以其前沿的智能化技术,为企业提供了从部署、运维到优化的全生命周期自治管理解决方案。本文将深入探索其核心能力,并聚焦其在数据处理服务场景下的最佳实现路径。
一、 前沿探索:腾讯云数据库自治服务的核心驱动力
腾讯云数据库自治服务的“自治”能力,源于多项前沿技术的深度融合:
- AI与机器学习引擎:这是服务的大脑。通过持续收集数据库的性能指标(如CPU、内存、IO、慢查询)、运行日志和SQL模式,利用机器学习算法建立性能基线,智能识别异常波动、预测潜在风险(如空间不足、性能瓶颈),并实现根因分析。
- 智能优化顾问:基于海量实例的运行经验与最佳实践模型,服务能够自动提供索引优化建议、SQL改写方案、参数调优配置等。例如,自动识别缺失索引的查询,并生成创建索引的脚本,在评估收益后可由管理员一键执行或自动执行。
- 自愈与自动化运维:面对常见的数据库故障,如主备切换、死锁处理、连接池耗尽等,系统能够根据预设策略或学习到的模式,自动触发修复流程,极大缩短平均恢复时间(MTTR),保障服务高可用。
- 资源弹性与成本优化:通过监控工作负载模式,智能预测资源需求,并结合腾讯云强大的底层资源调度能力,实现存储与计算资源的自动弹性伸缩。分析资源利用率,给出闲置资源识别与规格降配建议,助力企业降本增效。
二、 数据处理服务场景下的最佳实践
在数据处理服务(如ETL流水线、实时报表、数据API服务等)这一对数据库稳定性、性能与成本极为敏感的场景中,腾讯云数据库自治服务的价值尤为凸显。以下是关键的最佳实践:
实践一:智能负载管理与性能保障
数据处理任务往往存在周期性峰值(如凌晨的批量作业、白天的实时查询)。自治服务通过历史负载学习,能够提前预测峰值到来,并自动进行性能优化准备,如提前进行缓存预热、临时扩容只读实例以分担分析型负载。当出现异常慢查询影响整体流水线时,系统能快速定位问题SQL并提供优化方案,甚至自动终止资源占用过度的异常会话,确保核心任务队列顺畅。
实践二:全链路监控与异常诊断
数据处理涉及多库、多表的复杂操作。自治服务提供全局拓扑视图和跨实例关联分析能力。当数据同步延迟或ETL任务失败时,它能快速绘制出受影响的数据链路,并定位是源端负载过高、网络延迟还是目标端索引缺失导致的瓶颈,提供一站式的诊断报告,极大提升排障效率。
实践三:自动化弹性与成本控制
针对数据处理任务潮汐特性明显的场景,可以结合自治服务的智能弹性伸缩策略。例如,在非高峰时段自动将实例规格降至基础配置以节省成本;在大型批处理任务开始前,自动按需提升计算能力或增加只读节点,任务完成后自动缩容。这种“按需使用”的模式,在保证性能的同时实现了极致的成本优化。
实践四:安全合规与数据治理
数据处理服务需严格遵守数据安全规范。自治服务集成智能风险检测,可自动识别敏感数据访问模式异常、SQL注入攻击企图等安全威胁。能自动完成数据库漏洞扫描、权限审计报告生成,并协助完成数据脱敏、审计日志的自动化管理,为数据处理流程筑牢安全防线。
实践五:变更管理与无人值守运维
对数据库的 schema 变更(如加字段、改索引)是数据处理服务迭代中的高频操作。自治服务提供风险预评估的在线变更能力,模拟变更影响,并在低峰期自动执行变更窗口,实现“零 downtime”或最小影响变更,推动DevOps流程的自动化。
三、 展望:从自治到智能生态
腾讯云数据库自治服务的最佳实践,不仅止于减轻DBA的运维负担,其更深层的价值在于将数据库从被管理的“资源”转变为能够主动适应业务、驱动业务的“智能数据服务层”。通过与大数据平台、AI中台的更深层次集成,自治服务有望实现从单实例优化到跨平台数据流的全局智能调度,真正实现数据基础设施的完全自主、自优、自愈,为企业的数据价值挖掘提供源源不断的智能动力。
对于任何依赖数据处理服务的企业而言,拥抱腾讯云数据库自治服务,不仅是技术架构的升级,更是构建数据驱动型组织、赢得未来竞争的关键一步。